选择题 共15道
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15判断题 共10道
16 17 18 19 20 21 22 23 24 25编程题 共2道
26 27P479 202503GESP C++五级试卷-练习
选择题 共15道
登录后查看选项
登录后查看选项
03
假设双向循环链表包含头尾哨兵结点(不存储实际内容),分别为 head 和 tail ,链表中每个结点有两个指针域 prev 和 next ,分别指向该结点的前驱及后继结点。下面代码实现了一个空的双向循环链表,横线上应填的最佳代码是( )。
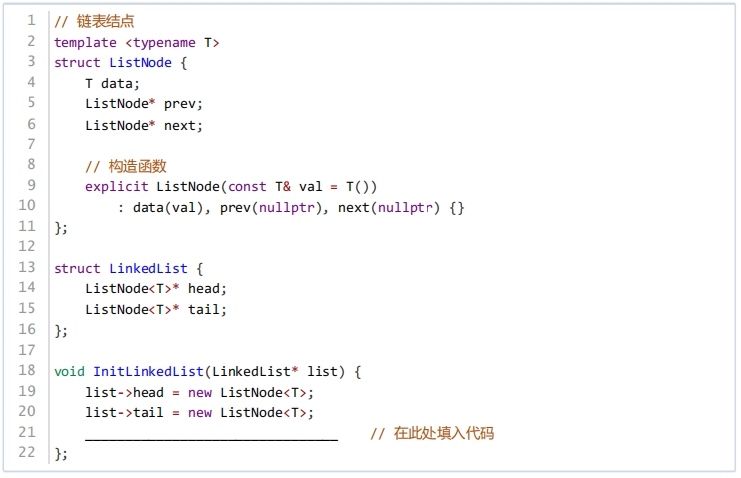
2分
登录后查看选项
04
用以下辗转相除法(欧几里得算法)求gcd(84, 60)的步骤中,第二步计算的数是( )。
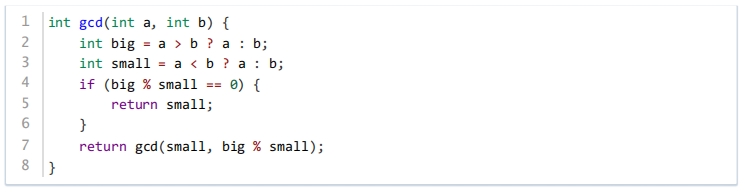
2分
登录后查看选项
登录后查看选项
06
下述代码实现素数表的线性筛法,筛选出所有小于等于n的素数,横线上应填的最佳代码是( )。
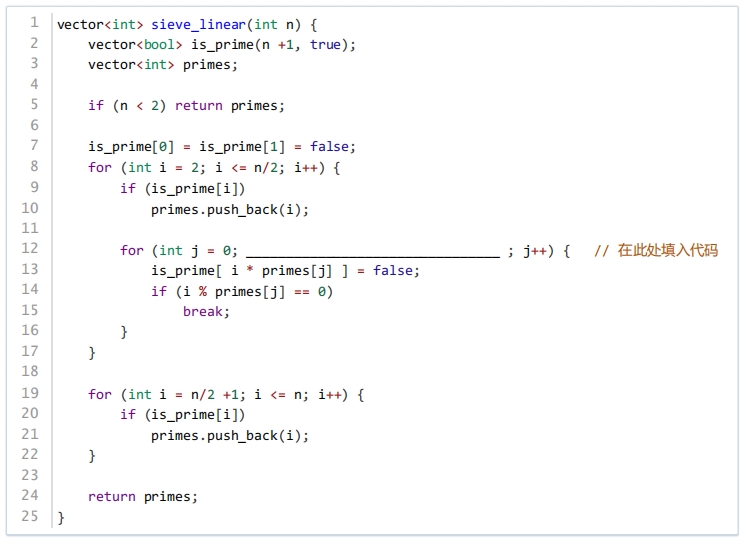
2分
登录后查看选项
登录后查看选项
08
对下面两个函数,说法错误的是( )。

2分
登录后查看选项
登录后查看选项
10
考虑以下C++代码实现的快速排序算法,将数据从小到大排序,则横线上应填的最佳代码是( )。


2分
登录后查看选项
登录后查看选项
12
下面代码实现了二分查找算法,在数组 arr 找到目标元素 target 的位置,则横线上能填写的最佳代码是( )。

2分
登录后查看选项
登录后查看选项
登录后查看选项
15
小杨编写了一个如下的高精度乘法函数,则横线上应填写的代码为( )。

2分
登录后查看选项